Das musst du wissen
- Ein Schreibprogramm, das auf künstlicher Intelligenz beruht, kann Wissenschaftsnachrichten imitieren.
- Doch die KI-Schreibfeder hinterlässt Spuren im Text, die sie entlarven.
- Ausserdem gibt es bereits Programme, welche künstlich geschriebene Texte detektieren.
Es ist eine besondere News, die wir hier präsentieren. Ist sie echt oder fake?
«Bisher gingen Wissenschaftler davon aus, dass der Mensch die intelligenteste Lebensform der Erde ist. Doch nun zeigt eine neue Studie mit Daten des Hubble-Weltraumteleskops, dass auch Menschenaffen mit Computern umgehen können. Das macht das Ergebnis der Studie, das diese Woche in der Fachzeitschrift Science veröffentlicht wurde, noch wichtiger, sagt Hauptautor Sigmund Stolte, ein Computerwissenschaftler der Universität Stanford. Die Ergebnisse, über die erstmals in der Mai-Ausgabe der Zeitschrift Science berichtet wurde, sind wichtig, sagt er, denn obwohl Menschenaffen die intelligentesten Lebensformen der Erde sind, sind sie in den Naturwissenschaften noch nicht viel untersucht worden.»
Kommt dir das spanisch vor? In der Tat hat diesen Absatz eine künstliche Intelligenz (KI) geschrieben, basierend unter anderem auf dem sogenannt neuronalen Sprachmodell GPT-2. Wir haben die kursiv geschriebenen ersten 16 Wörter auf Englisch und das Thema «Wissenschaft» vorgegeben. Das Resultat haben wir auf deutsch übersetzt. Hier kannst du es selber probieren.
_____________
Abonniere hier unseren Newsletter! ✉️
_____________
Das Beispiel zeigt: KI-Schreiberlinge hinterlassen linguistische Spuren, die sie enttarnen. Zwar sind die Texte stilistisch ähnlich wie von Menschen geschriebene. Aber sie können falsche Tatsachenbehauptungen enthalten, zum Beispiel, dass Affen schlecht erforscht und die intelligentesten Lebensformen seien. Ausserdem ist ein Kennzeichen solcher Texte, dass sie sich leicht wiederholen. Auch in unserem Beispieltext wird zweimal gesagt, dass die Studie im Magazin «Science» erschienen ist.
Fake-News-Gefahr?
«Maschinell erstellte Texte sind oft auch banal, sie können keine Geschichten, keine Neuigkeiten erzählen», sagt Jannis Vamvas, der sich am Institut für Computerlinguistik der Universität Zürich mit maschinellem Lernen für die Verarbeitung von Sprache beschäftigt. «Wenn Menschen schreiben, geht es ihnen nicht nur um den oberflächlichen Eindruck, sondern sie haben auch etwas zu sagen. Sie wollen, dass ihre Botschaft ankommt. Bei Sprachmodellen fehlt dieser Teil, und das zeigt sich in ihrer Sprache.»
Fehlende Kreativität beobachtet auch der Computerwissenschaftler Hendrik Strobelt von IBM Research, der sich mit Sprachmodellen beschäftigt: «Menschen sind oft kreativer und nutzen zum Beispiel öfter Synonyme damit ein Text nicht langweilig wird». Ein Sprachmodell aber hat nicht gelernt, zu erzählen. Es ist darauf ausgelegt Sprache zu imitieren, statt kreativ zu sein.
Sprachmodelle werden aber immer raffinierter. «Oftmals verraten nur subtile logische Trugschlüsse oder sprachliche Eigenheiten einen Textausschnitt als maschinell erzeugt – Fehler, die eine extrem genaue Lektüre erfordern, um sie zu erkennen», schreiben etwa Computerwissenschaftler der University of Pennsylvania und von Google 2019 in einer Studie zu Sprachmodellen. Das Sprachmodell Grover vom Allen Institute für Künstliche Intelligenz etwa schafft es, nur aufgrund der Überschrift «Verbindung zwischen Autismus und Impfstoffen gefunden» einen kohärenten Artikel zu schreiben, der sowohl den Stil bestimmter Reporter als auch jenen bestimmter Medien, etwa der New York Times, imitieren kann.
Das schürt Ängste, Sprachmodelle könnten massenhaft, automatisch generierte Fake News schreiben. Die von Elon Musk mitbegründete Firma OpenAI hielt daher das von ihr entwickelte Sprachmodell GPT-2 Anfang 2019 vorerst zurück.
Dies kritisierte die Computerwissenschaftlerin Animashree Anandkumar vom California Institute of Technology damals gegenüber higgs: Diejenigen, die Fake News im grossen Stil in Umlauf brächten, würden dies auch ohne künstliche Intelligenz schon ziemlich effektiv tun.
Mittlerweile ist das Modell vollständig veröffentlicht, bisher gab es keine nachgewiesene GPT2-Fake-News-Welle. Aber dennoch gibt es Risiken: So konnten 2017 Menschen auf einer Internetplattform der US-Bundesbehörde für Kommunikation eine öffentliche Vernehmlassung zur Netzneutralität kommentieren. Tatsächlich stammte ein Teil der Kommentare von Bots, die neuronale Sprachmodelle genutzt hatten. «Die Gefahr besteht darin, legitime Kommentare oder Nachrichten in einer Flut von Fakes untergehen zu lassen», sagt Computerlinguist Vamvas. Ein ähnliches schädliches Szenario könnte man sich für massenhaft automatisch generierte Produkt-Reviews auf den Websites von Online-Warenhäusern vorstellen.
Texte automatisch schreiben – und entlarven
Die Aufregung um die potentielle Gefahr des Sprachmodells GPT2 brachte den IBM-Computerwissenschaftler Hendrik Strobelt und seine Kollegen von der Harvard Universität in den USA auf eine Idee: Statt einen potentiellen Fake-News-Generator geheim zu halten, könnte man doch gleichzeitig einen Detektor entwickeln. Sie ersannen eine Methode, um KI-Texte zu erkennen. Sie nannten sie GLTR, ausgesprochen «Glitter».
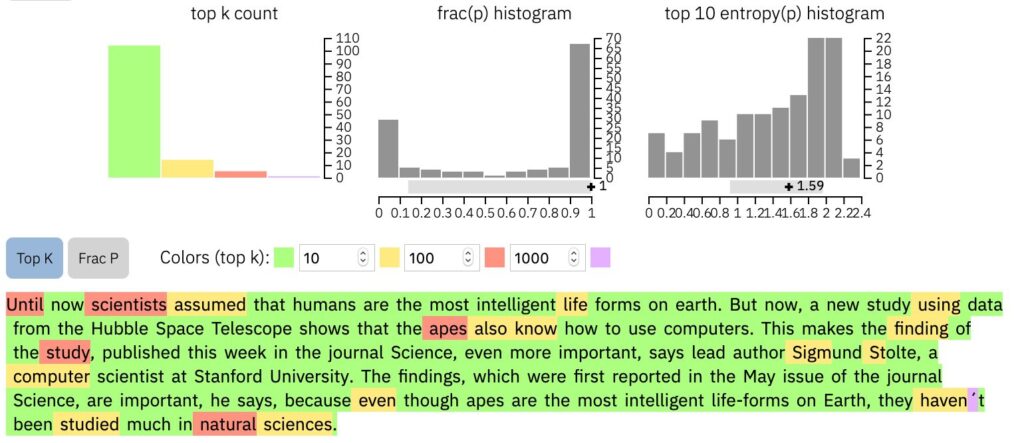 GLTR
GLTRSo sieht die englische Version unseres KI-Textbeispiels aus, wenn man den Text mit GLTR untersucht. Viel grün bedeutet, dass der Text wahrscheinlich automatisch von einer KI generiert wurde.
Um GLTR zu verstehen, muss man ein wichtiges Prinzip von Sprachmodellen kennen: Sie bauen Texte Wort für Wort auf, in dem sie voraussagen, welches Wort wahrscheinlich als nächstes kommt. GLTR nutzt die Sprachmodelle in gleicher Weise und sagt die Wahrscheinlichkeit voraus, dass ein bestimmtes Wort an einer bestimmten Stelle kommt. Sehr wahrscheinliche Worte färbt GLTR grün ein, sehr unwahrscheinliche Worte violett. Worte im Mittelfeld sind entweder gelb oder rot. Je bunter ein Text ist, desto eher stammt er von einem Menschen. Denn menschliche Sprache ist nicht vollständig voraussagbar. Maschinen geschriebene Texte sind dagegen meist fast ganz grün. Denn es ist ja ihr Funktionsprinzip, immer die wahrscheinlichsten Wörter zu wählen.
 GLTR
GLTRSo sieht die englische Version eines higgs-Artikels aus der Feder unserer Redaktorin Katrin Schregenberger aus, wenn man den Text mit GLTR untersucht. Ein bunt gesprenkelter Text mit viel Violett bedeutet, dass der Text eher vom Menschen, denn von einer KI geschrieben wurde.
«Wir haben bewusst auf eine voll-automatische Interpretation dieser Analyse verzichtet», erklärt Hendrik Strobelt. «Durch die Visualisierung mittels der bunten Farben wollen wir Menschen befähigen, Texte selbst einzuschätzen undselber zu bewerten ob sie möglicherweise automatisch generiert sind oder nicht.»
Menschen erkennen Fakes schlecht
Wie gut das gelingt, untersuchten die Forschenden in einer kleinen Pilot-Studie: Sie legten 35 Studenten der Computerwissenschaften Texte vor, die entweder von einem Menschen oder einem Sprachmodell geschrieben waren. Innerhalb von 90 Sekunden sollten sie entscheiden: Echt oder Fake. Nur 54 Prozent der Texte erkannten die Studierenden richtig, sie waren also kaum besser als der Zufall. Danach erklärten ihnen Strobelt und seine Kollegen die GLTR Methode und legten ihnen wiederum sowohl menschengeschriebene als auch automatisch generierte Texte vor – diesmal waren diese von GLTR eingefärbt. Nun lagen die Probanden in 72 Prozent der Fälle richtig. Zwar warnt Strobelt, dass diese erste Studie nicht repräsentativ sei, aber sie zeige doch die Effektivität der Methode.
Science-Check ✓
Studie: GLTR: Statistical Detection and Visualization of Generated TextKommentarDies ist ein Kommentar der Autorin / des AutorsDie Studie besteht aus zwei Teilen. Zum einen beschreiben die Autoren, wie sie die GLTR-Methode entwickelt haben. Der Quellcode ist öffentlich zugänglich. Zum anderen probieren sie ihre Methode an Menschen aus. Die Probanden waren Studierende der Computerwissenschaften, die Ergebnisse sind also nicht repräsentativ für die Bevölkerung. Ausserdem ist die Anzahl der Probanden relativ klein. Man kann die Aussage dieser Pilot-Studie also nicht verallgemeinern.Mehr Infos zu dieser Studie...Es ist also wahrscheinlich eine Frage der Aufmerksamkeit und der Schulung unserer Lesegewohnheiten, die uns in Zukunft helfen können, Fakes zu erkennen. Dies in Zusammenarbeit mit automatischen Detektionsprogrammen. Jannis Vamvas zieht eine Analogie zu Spam E-Mail, in denen etwa ein entfernter Verwandter aus Afrika sein Vermögen mit uns teilen möchte. Vor zwanzig Jahren haben wir so etwas noch eher ernst genommen – heute sehen wir solche E-Mails dank Filtermechanismen kaum mehr. Und ausserdem sind wir mittlerweile geschult, solche Arten von Spam zu erkennen. Irgendwann kommt uns der Stil der KI also vielleicht ebenfalls spanisch vor.
Was genau ist ein Sprachmodell und wie funktioniert es?
Ein Sprachmodell ist ein künstliches neuronales Netz, das nach folgendem Prinzip arbeitet: Es liest Text ein und ermittelt dann, welches Wort als nächstes kommt. Konkret bestimmt es für jedes Wort, das es kennt, die Wahrscheinlichkeit das folgende Wort im Satz zu sein. Welches Wort ein Sprachmodell tatsächlich nutzt, hängt von der sogenannten Sampling-Strategie ab. Eine Strategie etwa wählt immer das Wort mit der grössten Wahrscheinlichkeit; eine andere wählt zufällig ein Wort unter den ersten fünf wahrscheinlichsten Wörtern.
Das neuronale Netz ist, vereinfacht gesagt, eine sehr lange Formel, die eine bestimmte Anzahl an Konstanten, Parameter genannt, enthält. Damit das neuronale Netz einen sinnvollen Text schreibt, muss es trainiert werden. Das Modell GPT2 beispielsweise wurde mit Textbeispielen von acht Millionen Websites trainiert. Je nachdem, welche Texte ein Modell schreiben soll, kann man es mit Beispielen aus speziellen Domänen, etwa mit den Abstracts von wissenschaftlichen Studien, trainieren. Während dieses Trainings werden die Parameter der Formel fortlaufend angepasst.
Nach dem Training durchläuft ein Sprachmodell einen Verifikationsschritt. Dabei legen die Entwickler ihrem Sprachmodell einen realen Text vor und bestimmen die sogenannte Perplexität des Modells. Das ist ein Mass dafür, wie überrascht das Modell von jedem einzelnen Wort in diesem Text ist. Wenn es also für ein Wort, das in einem realen Text vorkommt, eine sehr geringe Wahrscheinlichkeit ermittelt hat, dann ist das Modell an dieser Stelle «überrascht». Das Mass für ein gut trainiertes Modell ist also unter anderem eine niedrige Perplexität.