Das musst du wissen
- Die Wissenschaft steht vor einem Problem: Studienergebnisse lassen sich nur schwer wiederholen und damit validieren.
- Diese sogenannte Reproduzierbarkeit von Studien ist aber wichtig, um aus einzelnen Ergebnissen Fakten zu erschliessen.
- Denn: Eine Studie macht noch keinen Fakt.

Leonhard Held
Leonhard Held ist Leiter des Center for Reproducible Science der Universität Zürich und Professor für Biostatistik an der Universität Zürich.
Herr Held, ab wann wird Forschung eigentlich zum Fakt?
Ich arbeite in der medizinischen Forschung und auch da dreht sich alles um die Frage: ab wann können wir sicher sein, dass ein neues Medikament wirkt? Den Aufsichtsbehörden ist es nicht genug, wenn eine Studie zeigt, dass ein signifikanter Effekt vorliegt, sondern sie muss wiederholt und das Ergebnis bestätigt werden. In anderen Disziplinen ist das noch nicht standardisiert der Fall. Es gibt auch keine Anreize: Für Wissenschaftler ist es eine höhere Auszeichnung, wenn sie etwas Neues entdecken.
Kommen Wiederholungsstudien denn oft zu anderen Schlüssen?
Ja. Ein grosses Replikationsprojekt in der Psychologie, bei der hundert Studien noch einmal durchgeführt wurden, erweckte vor einigen Jahren Aufsehen, weil zwei Drittel der replizierten Studien die Ergebnisse der Orginalstudien nicht wirklich bestätigen konnten. Es gab dann auch Umfragen unter Wissenschaftlern, die zeigten, dass viele Forscher nicht einmal daran glaubten, ihre eigenen Erkenntnisse reproduzieren zu können. Das löste eine Krise aus.
Weil das die Resultate der Forschung in Frage stellt?
Eher, weil es zeigt, dass die Standards für empirische Forschung nicht genügend hoch sind. Das zieht sich über alle Disziplinen hinweg, ganz prominent ist die Psychologie, das zieht aber auch Kreise in der medizinischen Forschung oder in den Naturwissenschaften.
Eine Studie macht also noch keinen Fakt…
Richtig. Das Problem ist im Moment, dass sehr viele Erkenntnisse publiziert werden und an die Öffentlichkeit gelangen, die sich im Nachhinein als gar nicht haltbar erweisen. Nehmen wir als Beispiel die Headline „Kaffee verursacht Krebs“. Vielleicht hat eine Studie Hinweise dafür gefunden, vier weitere Studien haben das aber nicht. In den wissenschaftlichen Fachzeitschriften lesen wir aber nur von der einen Studie. Das nennt sich publication bias: Journals publizieren vor allem positive Ergebnisse. Das verzerrt unser Bild von der Realität stark.
Was kann man dagegen tun?
Es gibt mittlerweile die sogenannten „registered reports“: da reicht man bei den Fachzeitschriften das Manuskript ein, bevor man die Studie durchführt. Da weiss man noch nicht, was rauskommt. Wenn das Journal das Manuskript akzeptiert, gibt es die Garantie, dass die Ergebnisse publiziert werden – egal ob sie positiv oder negativ ausfallen. Einige Zeitschriften machen das bereits so, aber bei weitem noch nicht alle.
Was heisst es eigentlich, eine Studie zu reproduzieren?
Es gibt im Wesentlichen drei Definitionen. Die Erste: dass ein zweiter Forschender mit exakt den gleichen Daten und exakt dem gleichen Computerprogramm zu den gleichen Ergebnissen kommt. Das ist Reproduzierbarkeit im engeren Sinne. Die zweite Form heisst auch oft Replizierbarkeit und geht einen Schritt weiter: angenommen ich wiederhole die Studie mit neuen Probanden, bekomme ich dann ein vergleichbares Resultat?
Und die dritte Definition?
Die Dritte zeigt, wie kompliziert das Ganze ist: wenn ich exakt den gleichen Datensatz unterschiedlichen Forschern gebe, kommen die dann alle zum gleichen Schluss? Das ist eben auch nicht so, weil unterschiedliche Forschergruppen oft unterschiedliche Methoden verwenden. Und je nach Methode kommt eventuell etwas anderes raus. Es gab da letztes Jahr ein recht eindrückliches Beispiel, bei dem ein und derselbe Datensatz von 29 verschiedenen Forschergruppen analysiert wurde. Die Variation der Ergebnisse war doch recht beachtlich.
Auf die Ergebnisse aus der Forschung kann man sich also nicht immer verlassen?
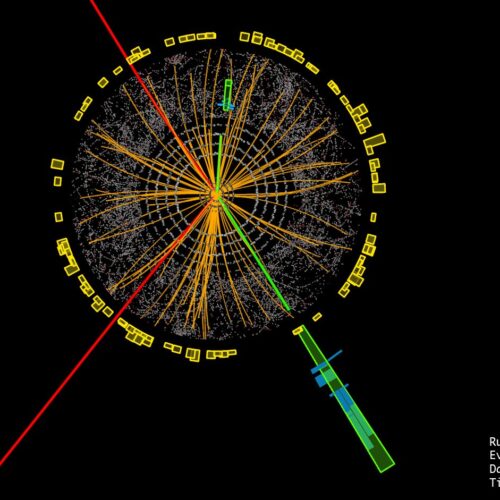
Es gibt natürlich immer Unsicherheit. Die Frage ist, wie viel lässt man zu? Wie gross sollen die Fehlerraten sei? Das heisst: mit welcher Wahrscheinlichkeit ist dieses Resultat jetzt wahr? Die kann man statistisch in den Griff bekommen. Ich kann etwa sicherstellen, dass die Fehlerrate kleiner als 1 Prozent ist. Ein sehr schönes Beispiel ist die Entdeckung des Higgs-Boson: Auch da gab es Fehlerraten, aber die wurden so klitzeklein gehalten, dass die Existenz des Teilchens trotzdem als Fakt gilt. Auch dort war die Unsicherheit nicht 0, sondern 10 hoch minus sieben oder ähnlich, also sehr klein.
Weshalb halten die Wissenschaftler die Fehlerraten nicht immer so klein?
Das geht nicht bei jeder Studie. Bei Experimenten kann der Wissenschaftler die meisten Faktoren kontrollieren, bei Beobachtungsstudien geht das nicht. Der Klimawandel ist ein gutes Beispiel: wir können nicht eine zweite Erde nehmen und da mal den CO₂-Ausstoss nicht erhöhen. Deswegen ist das da schwieriger, zu hieb- und stichfesten Ergebnissen zu gelangen. Evidenz braucht bei solchen Themen mehr Zeit.
Das grosse Problem ist: Um die Fehlerraten klein zu halten, braucht man viele Patienten, viele Probanden, viele Tiere. Das ist häufig nicht so einfach umsetzbar.
Dann könnte man wenigstens bei Experimenten im Labor niedrige Fehlerraten verwenden, oder?
Das grosse Problem ist: Um die Fehlerraten klein zu halten, braucht man viele Patienten, viele Probanden, viele Tiere. Das ist häufig nicht so einfach umsetzbar. Ein Arzt, der untersucht, ob ein bestimmtes Medikament eine seltene Krankheit heilt oder lindert, ist wahrscheinlich froh, wenn er in einem Jahr 20 Patienten bekommt. Mit so wenigen Patienten können Sie die Fehlerraten aber nicht klein halten. Die Fehlerraten sind dann gross – vielleicht sogar zu gross.
Fehlerraten, Wahrscheinlichkeiten – rettet die Statistik die Objektivität?
Das ist eben leider nicht so. Es gibt auch in der Statistik unterschiedliche Philosophien und Methoden. Im Kern dreht sich alles um die Frage der Wahrscheinlichkeit und der Signifikanz, das ist sehr technisch. Signifikante Ergebnisse werden zudem häufig gleich gesetzt mit wahren Ergebnissen: Wenn es signifikant war, ist es wahr. Das stimmt überhaupt nicht. Auch wenn ein Ergebnis signifikant war, kann es eben falsch gewesen sein. Denn man hat eben diese Fehlerraten und die sind häufig gar nicht so klein.
Ab wann ist eine wissenschaftliche Erkenntnis denn nun ein Fakt? Wie bildet sich ein wissenschaftlicher Konsens?
In der medizinischen Forschung wird die Evidenz zu einer bestimmten Fragestellung durch systematische Überblicke aller relevanten Studien zusammengefasst. Da gibt es klar definierte Regeln, wie die Qualität von Studien bewertet wird. Auch die Ergebnisse von nicht-publizierten Studien werden manchmal berücksichtigt. Solche Meta-Analysen können zu gesicherten Erkenntnissen, also gesicherten Fakten, führen.
Ist mehr immer besser? Sind Studien mit grossen Datenmengen verlässlicher?
Bei experimentellen Studien würde ich das so sagen. Je grösser die Fallzahlen, desto glaubwürdiger ist das. Bei korrelativen Studien, also Beobachtungsstudien, kommt ein anderer Faktor ins Spiel, nämlich die Qualität der Daten. Das ist ein Aspekt, der häufig übersehen wird bei der Diskussion der Chancen und Risiken von Big Data: dass diese Datensätze häufig so schlecht sind, dass selbst die grosse Fallzahl nichts mehr hilft.
Was macht diese Qualität aus?
Wichtig ist, dass der Datensatz, den man hat, repräsentativ ist für die Gruppe, für die man sich interessiert. Und das ist eben häufig bei Big Data nicht der Fall. Stellen Sie sich vor, sie machen eine Studie mit einer App und hoffen, dass die Benutzer dort ihre gesundheitlichen Probleme dokumentieren. Eine 90-Jährige wird da nicht teilnehmen, sondern Sie werden nur IT-affine, wahrscheinlich prominent junge Leute haben.
Nehmen wir an, uns interessiert die Gruppe der IT-affinen Jungen.
Dann ist bei Big Data das Problem, dass häufig viele Daten fehlen. Der User soll Daten eingeben, hat aber irgendwann vielleicht keine Lust mehr. Oder er will das Gewicht nicht angeben, weil es ihm peinlich ist. So entstehen viele Verzerrungen. Bei Studien, die im Vorhinein geplant sind, haben Forscher bessere und vollständigere Daten und kontrollieren auch, wie diese erhoben werden.
Forscher sollten nicht mehr auf ihren Daten sitzen wie auf einem Goldschatz.
Wie können wir denn nun die Qualität der Forschung verbessern?
Indem man sie reproduzierbar macht. Das bedingt einheitliche Standards – und, dass die Daten, auf denen Studien beruhen, ebenfalls publiziert werden, damit andere Forscher nachrechnen können. Das nennt sich Open Science. Natürlich gibt es nicht öffentlich zugängliche Daten, sei es wegen Datenschutz oder aus anderen Gründen, das zeigt sich gerade in der klinischen Forschung. Aber auch dort kann der Zugang zu den Daten zunehmend eingefordert werden. Forscher sollten nicht mehr auf ihren Daten sitzen wie auf einem Goldschatz. Das ist zentral, um die Glaubwürdigkeit der Forschung zu erhöhen.
Scientifica 2019
Scientifica vom 30. August bis zum 1. September an der ETH und der Universität Zürich: Die Scientifica 2019 widmet sich der Frage, wie Fakten von Fiktionen unterschieden werden können. Das Thema der reproduzierbaren Forschung wird am Science Café «Therapien für die krankende Wissenschaft» diskutiert.
Informationen unter www.scientifica.ch